Stacking OpenSpec and Superpowers, Three Weeks Later: Five Frictions and a Plugin

I published Stacking OpenSpec and Superpowers on April 19th — three weeks ago. The headline number was concrete: a refactor shipped in three hours, eighty-six new tests, zero regressions. I meant every word of it. At that time, that stack — OpenSpec's propose/apply/archive triplet (the framework also offers explore, but I'd been skipping it) over the three Superpowers skills I lean on most (brainstorming, test-driven-development, requesting-code-review) — was the best discipline I'd found for spec-driven development with AI in the loop.
What I didn't say — because I didn't know yet — is that the stack had five hidden cracks. They didn't show on a single refactor. They showed up the third, fourth, fifth time I ran it on a new project, when the workflow had to carry weight rather than win a sprint.
This post is the evolution. It's what I'd add to that earlier post if I had to write it again today, after running the stack across a couple more projects — most cleanly on python-agent, where I deliberately let each friction point speak for itself before designing the fix.
I'll spend the first half listing the five friction points (where the earlier stack hurt) and the second half on what I did about them (a three-step methodology abstraction plus four command-level fixes). Then I'll show the four-command, four-phase shape I ended up with, why this is still agile in the form you'd recognize, and the plugin I packaged so you can run the whole thing without re-reading either post.
If you haven't read the earlier post, the original entry point is there. This post assumes OpenSpec's four-command base (explore/propose/apply/archive) and the three Superpowers skills I just mentioned (brainstorming, test-driven-development, requesting-code-review).
One thing I want to flag up front: nothing in the evolution is a clever invention. Each fix was a response to a specific moment where the earlier stack produced output I didn't trust. The pattern that emerged is practice → friction → fix → harden. Methodology evolves by being run, not by being designed. The plugin at the end is the byproduct, not the goal.
The Five Friction Points
Friction 1 — The brainstorm UI vanishes at propose time
Superpowers' brainstorming skill has a visual-companion flow that opens a browser preview and lets you iterate on mockups. It's one of the best parts of the skill — for a UI-heavy feature, you actually see the design before you write any code.
The problem is what happens next. You finish brainstorming with a perfectly good UI design. You hand off to OpenSpec's propose. And propose produces a plan that does not reference the mockup at all.
Why? Because the link between brainstorming output and propose input is whatever you remember to put in the prompt. The UI design lives in the brainstorming session's conversational memory. By the time you're typing propose, you're starting a new context. Unless you explicitly re-paste the mock — and most people don't, because the mock isn't a file — the design is gone.
I noticed this on the third feature in python-agent. I'd spent twenty minutes in visual-companion settling on a particular dashboard layout. Then I ran propose. The resulting spec.md described a generic table view that had nothing to do with the layout I'd just designed. Two minutes of "wait, this isn't what we agreed on" later, I was manually re-stating constraints that should have been carried over.
The pattern is: conversational design is volatile; the next session won't see it unless it's a file.
Friction 2 — Brainstorm doesn't understand the codebase
Superpowers' brainstorming is grounded in text — your description, the conversation, and whatever documents you've explicitly attached. It does not read your code.
That means: brainstorm can produce a design that's technically reasonable but operationally wrong. It can propose a new BaseAgent class while your project already has one. It can suggest a database schema that ignores the migration constraints you've been carrying for two months. It can recommend a third-party library that conflicts with your existing dependency tree.
You catch some of this at propose time, because OpenSpec's propose does read the codebase. But by then, you're rewriting more of the design than you should be. The earlier this constraint enters, the better.
The fix turned out to be obvious in retrospect: OpenSpec has an explore step that does read code. The right order isn't brainstorm → propose. It's explore → brainstorm → propose. Explore first, ground the brainstorm in actual codebase facts, then design. I'll come back to this.
The pattern is: a design grounded in text alone will drift from a codebase grounded in code.
Friction 3 — Skill triage depends on remembering, not on mechanism
This was the most expensive friction because it hid behind a working command. When I ran /opsx:apply, the intent was: use Superpowers' test-driven-development skill to execute each task, then invoke requesting-code-review on the result. That sequence is what makes apply close the loop properly — TDD for behavior, paired review for spec drift.
The problem: nothing forced that sequence. apply is a command; the Superpowers skills are skills. They get triaged into the session only if my prompt names them. If I forgot to write "use the tdd skill" and "then run code review" — and I forgot often, because the sequence felt obvious in my head — apply ran without TDD discipline, without paired review, and produced code that looked fine but skipped both safety nets.
The deeper pattern shows up everywhere artifacts cross tools: between brainstorm and propose, between propose and apply, between apply and archive. Natural language is the linking medium. You say "use the design from earlier" and the AI does its best. If your prompt mentions the spec without specifying which sections matter, the AI picks its own sections to honor. If a constraint emerged in brainstorm and didn't make it into the prompt for propose, the constraint is gone.
In a one-off project, you absorb the cost as edit cycles. In a methodology you're trying to apply repeatedly, the lossiness compounds. Each step degrades the signal a little, and by the time apply runs, you're three lossy links away from the original intent.
The pattern is: prompt-based linking is fine for one project. It's a tax for ten — and the tax hides as 'code that looked fine.'
Friction 4 — Apply has no UI validation
TDD is well-handled in this stack. Superpowers has a test-driven-development skill, and OpenSpec's apply runs against your test suite. For backend behavior, this closes the loop nicely — red, green, refactor, commit.
What it doesn't close is visual correctness. If the brainstorm produced a UI design, and the spec described layout constraints, and apply writes the frontend code, there's no automated check that what shipped looks like what was designed. You read the test output, see green, and assume it's done. Then you actually open the page, and the spacing is wrong, the button is in the wrong corner, or the table has the wrong columns.
The frustrating thing is that this is solvable — visual diff tools exist, headless screenshots exist — but it's not in the base stack. It's the kind of thing you have to graft on yourself, and most people don't, because they don't realize they need to until they ship something that passes its tests and still doesn't look right.
The pattern is: the loop that closes is the one with mechanism. Behavioral correctness has TDD; visual correctness has nothing — and 'nothing' compounds.
Friction 5 — Archive without retrospection means repeating yourself
In the earlier stack, archive was the last command. It summarized what got done, marked the feature as closed, and that was it. On paper it was the retrospection step. In practice it was a closing ceremony.
Three things didn't happen automatically and so didn't happen at all:
- Pitfalls never reached CLAUDE.md. When I hit a constraint during
apply— say, "this database adapter doesn't support batch upserts the way I assumed" — the constraint went into a commit message and conversation memory, then vanished. The next project on a similar adapter would re-discover the same thing. - The spec never migrated to the README. A spec is a working document; a README is a durable one. New readers landing on the project a year later shouldn't have to spelunk through
./openspec/archives to learn what the project does. The migration step existed nowhere. - Lessons stayed in conversation memory. What worked, what didn't, what I'd do differently next time — these are the highest-value artifacts a project produces. Without a file to land in, they evaporated.
The pattern is: a retrospective that lives in conversation is a retrospective that ran exactly once. Lessons compound only when they leave the session.
The Evolution — Three Abstractions and Four Command-Level Fixes
Before listing the per-command improvements, there's a layer above them that matters more: the methodology itself went through three abstractions. Each abstraction was forced by the friction at the previous level.
Abstraction 1 — Prompt + LLM as the workflow medium
The earliest version of this stack lived entirely in prompts. I described what I wanted to OpenSpec and Superpowers using natural language, paste-by-paste. The goal at this stage was simply to prove the integration worked — that explore could feed brainstorm, that brainstorm could feed propose, that the cross-tool handoff produced something coherent end-to-end. Soft integration was the right call for the proof: it kept me focused on whether the combination was viable, not on how to make it durable.
It worked for one project. It worked less well for the second. It started producing inconsistent artifacts by the third. The friction was the linking problem (Friction 3): NL is a soft medium, and softness compounds. The proof was done; the production version needed bones.
Abstraction 2 — OpenSpec custom schemas and commands
The next level traded soft integration for schema. Custom OpenSpec schemas defined what brainstorm, propose, and archive were supposed to produce — specific file shapes, specific section names, specific cross-references. Custom commands made the sequences enforceable inside Claude Code rather than living in my head. The workflow stopped being a story I told and started being a contract the tooling could check. Same idea as the first abstraction; the medium got harder.
Abstraction 3 — A Claude plugin, decoupled from any one project
The third abstraction earned itself when the flow felt solid enough to recommend. Once the workflow was a contract, the contract could travel. I packaged the schemas, the commands, and the cross-tool wiring into a Claude plugin. A Claude plugin is a discoverable, installable bundle of skills and commands that Claude Code loads at session start — so the workflow shows up in any project I work in (and, more importantly, in any project someone else clones it into). The plugin is the methodology made portable. That's the bar I waited for — not personal convenience, but something I'd hand to a colleague without a long explanation.
Each level of abstraction was forced, not chosen. The friction at level 1 drove level 2. The cost of re-creating level 2 in every project drove level 3. None of it was designed up front; each layer earned its existence by being needed.
Below those three meta-abstractions sit four concrete command-level fixes that close the five frictions above. The mapping isn't one-to-one: Fix 1 closes Frictions 1 and 2 together (mocks-as-files + explore-first), Fix 2 closes Friction 3's lossy-linking half, Fix 3 closes Friction 3's skill-triage half and Friction 4 together (TDD + visual diff + code review baked into the command), Fix 4 closes Friction 5. These are the parts you actually run.
Fix 1 — Explore first, then brainstorm with mocks as files
The new order: /opsx:explore runs before the rest of the workflow, and inside it, the agent reads the codebase first and then invokes superpowers:brainstorming for the design pass — not the other way around. By the time you're designing, the AI already knows the codebase shape.
Inside that brainstorming pass, two changes matter. First, when the feature is UI-heavy, the mock isn't generated as a markdown sketch — it's generated as an HTML file. There's a recent note from Anthropic engineers that HTML is a better medium than markdown for describing UI requirements, and that matches my experience. HTML carries layout, spacing, visual hierarchy, and interaction hints in one artifact. Markdown carries vibes.
Second, visual-companion is told explicitly to save the mock to a file path and the brainstorm output is told to reference that path. The requirement document /opsx:explore produces now has a line like UI mock: ./mocks/dashboard.html. The mock is a file. It persists across sessions. The next step can read it.
The cost: a few more minutes per feature to save HTML mocks. The benefit: every downstream step now has a stable visual reference. Friction 1 stops happening because the conversation isn't the only place the design lives.
Fix 2 — propose enforces linked requirements and linked mocks
propose produces three artifacts: spec.md, design.md, task.md. In the earlier stack, these were generated based on whatever the prompt mentioned. Now, propose asks an upstream question before generating anything: is the requirement reviewed? is the mock attached?
If the answer is "no requirement file" or "no mock referenced," propose either refuses or prompts you to make the linkage explicit. This sounds heavy-handed. In practice it's a five-second check at the start of propose that prevents twenty minutes of misaligned spec.
The mechanism that makes this enforceable is that propose now reads structured input. The requirement is a file. The mock is a file. The spec references both by path. The task.md it produces says "task 3: implement dashboard per ./mocks/dashboard.html and ./spec/requirements.md section 2." This is what friction 3 — prompt-based linking is soft — becomes when you give it bones.
Fix 3 — apply runs TDD plus visual diff
apply now invokes Superpowers' test-driven-development skill faithfully — write the failing test, watch it fail, implement, watch it pass, commit. That's the closing loop for behavior, and it runs by default rather than by prompt reminder.
For UI features, apply also runs a visual diff against the saved mock. The mechanism is straightforward: headless browser screenshots the rendered UI, compares to the mock at a tolerance threshold, flags differences. This isn't a hard gate — visual diffs have legitimate false positives — but it's a signal that the implementation deviates from the design, and the signal arrives during apply rather than after I open the page myself.
The other addition inside /opsx:apply is that superpowers:requesting-code-review runs as a paired step at the end of every task group, not as a separate command I have to remember. The reviewer subagent reads the spec, reads the code, and flags drift. This catches the failure mode where the test passes but the implementation isn't what the spec actually said — the same failure mode that human pair programming catches. And because it's part of the task template that /opsx:propose injected, it fires whether or not I think to ask for it.
Fix 4 — archive becomes retrospection, not summary
archive now does three things, each with a mechanism:
-
Retro log. A short prompt at the end of
archive: what did you learn that you didn't know going in? What constraint emerged that the spec missed? What would you do differently next time? The output goes to./retros/YYYY-MM-DD-<feature>.md. Three or four lines is enough. The point is that the lessons leave conversation memory and enter the file system. -
CLAUDE.md update. New pitfalls or constraints discovered during apply get appended to
CLAUDE.mdunder a "constraints" or "pitfalls" section. This means the next session — whether yours or someone else's — sees the constraint at session start. The pattern of repeating the same mistake across projects is what this fixes. -
README migration. When
archiveruns, the spec's "what this does" section is migrated to the README's user-facing summary. Specs are working documents; READMEs are durable. The migration step ensures that anyone landing on the project a year later gets the spec's essence without spelunking through./openspec/.
The pattern across all three is that archive makes future you (and future readers) inherit the lessons of present you. The earlier archive was a checklist. The new archive is the mechanism Agile retrospectives were always supposed to be.
Four Commands, Four Phases
Here's what the evolved stack looks like end-to-end. The shape is OpenSpec's: four /opsx: commands, one per phase — that's everything you type. The Superpowers skills in the right-hand column run inside those commands, triaged automatically.
| Phase | Command | What it does | Embedded Superpowers skills | Closes |
|---|---|---|---|---|
| 1. Ground | /opsx:explore | Reads codebase, drafts <topic>-requirements.md (Status: DRAFT → REVIEWED), generates HTML mocks for UI work | superpowers:brainstorming (self-review pass + visual-companion for UI mocks) | Frictions 1 + 2 |
| 2. Plan | /opsx:propose | Generates proposal.md + capability specs + design.md + tasks.md. Rejects DRAFT requirements at the gate; injects RED/GREEN pairs, MOCK + VISUAL DIFF sandwich, and code-review checkpoints directly into tasks | Task templates encode superpowers:test-driven-development and superpowers:requesting-code-review patterns | Friction 3 (lossy linking) |
| 3. Build | /opsx:apply | Executes tasks.md: RED → GREEN → (MOCK → VISUAL DIFF if UI) → code review per group, with manual-ops pauses where needed | superpowers:test-driven-development (session-start), superpowers:requesting-code-review (per group), superpowers:verification-before-completion (final group) | Frictions 3 (skill triage) + 4 |
| 4. Close | /opsx:archive | Archives the change, fills capability spec Purpose, updates specs README + CLAUDE.md pitfalls + (conditional) project README, prompts dev log | — (cleanups are built into the command itself) | Friction 5 |
Four commands, four phases. The phases match what you'd expect from any spec-driven workflow — ground in reality, plan, build, close. The difference from the earlier stack: each command has mechanism attached, and that mechanism includes invoking the right Superpowers skills automatically. The friction points stopped happening when skill triage moved from "things I have to remember to write in the prompt" to "things the command does by default."
The flow as a single picture:
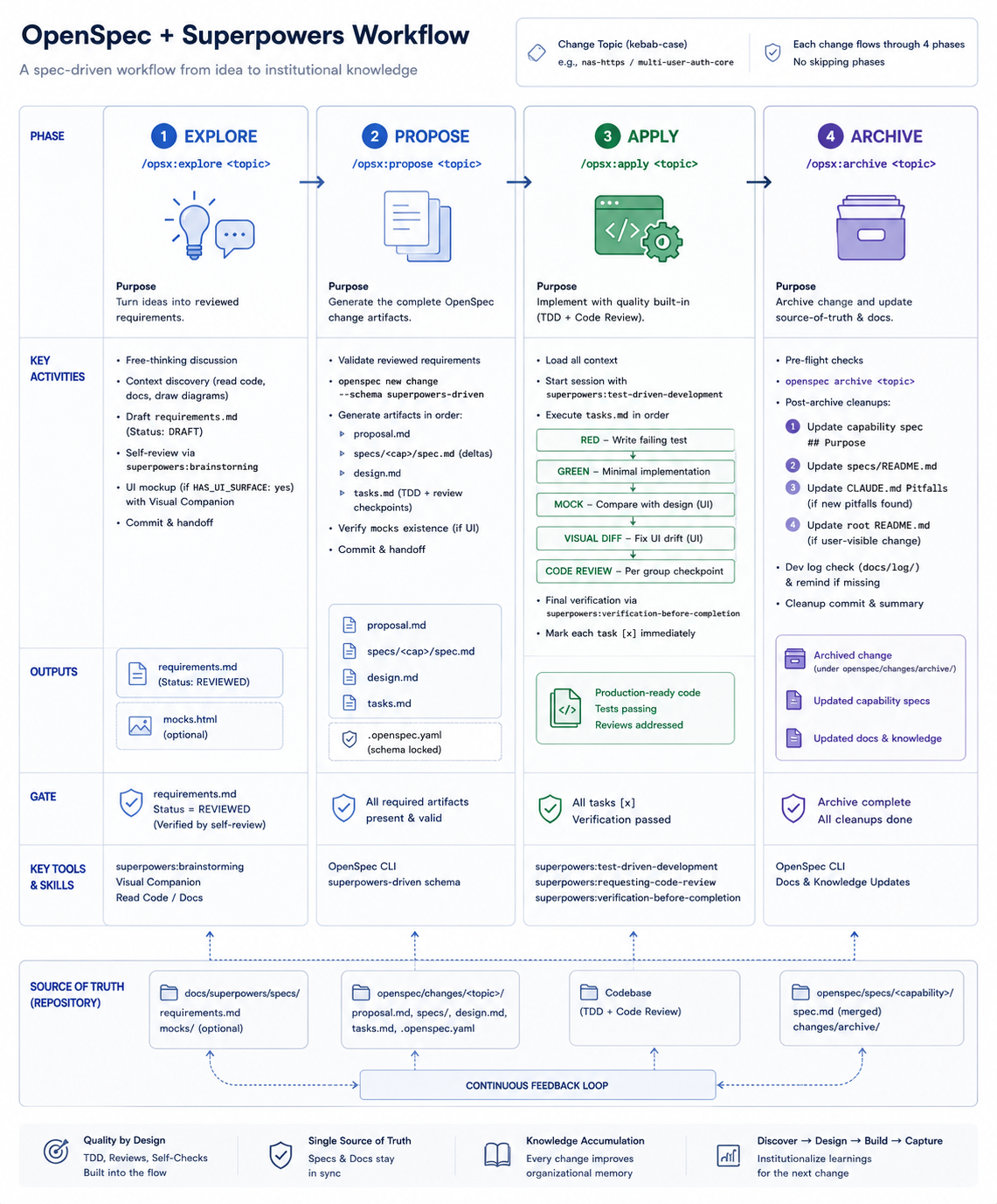
Reading the diagram alongside the table makes one thing clear: the loops aren't optional. /opsx:apply returns to /opsx:propose when the spec is wrong. /opsx:archive returns to /opsx:explore when the retrospection surfaces a constraint that should have been a requirement. The methodology isn't linear because the failures aren't linear.
Agile, Made Operational
I wrote at length earlier this year about why Agile principles survive the AI coding transition. That post argued the principles still hold — TDD becomes the closing loop, small iterations get smaller, pair programming becomes pairing with an AI, retrospection gets formalized in tools like SpecKit and OpenSpec.
This post is what those principles look like when they become commands.
/opsx:exploreis small iterations + plan before execute + pair programming — calibrate the unit of work against the codebase, brainstorm the design withsuperpowers:brainstorminginside, save the mock to a file before handing off/opsx:proposeis working software as the measure of progress — the spec exists to produce code that runs, complete with RED/GREEN/VISUAL-DIFF/code-review tasks baked into the plan before any code is written/opsx:applyis TDD as the closing loop + pair programming, formalized —superpowers:test-driven-developmentandsuperpowers:requesting-code-reviewaren't optional add-ons here; they're invoked at session start and run on every task group/opsx:archiveis retrospection — capability specPurposefilled, specs README updated, CLAUDE.md pitfalls captured, dev log prompted
The earlier post said: file provides memory, you provide discipline. This post is the discipline.
There's a smaller observation worth surfacing. I didn't design the four command-level fixes to embody Agile principles. I designed them to fix four specific things that hurt — the four fixes that close the five frictions above. Agile fell out of the shape because Agile was the underlying response to similar friction in a pre-AI world. Methodology converges when the constraints converge.
What this evolution did, in one sentence: it took the Agile ideas I grew up reading and baked them into the skills and the workflow itself, so the discipline runs whether or not I remember to invoke it.
Ship — opsx-superpowers
The plugin is at github.com/austinxyz/opsx-superpowers. The full workflow doc is at docs/workflow.md, including the diagram of how the four commands chain together and the maintenance routine for keeping the fork in sync with OpenSpec upstream.
Three-step start:
-
Clone and install.
git clone https://github.com/austinxyz/opsx-superpowers ~/.claude/plugins/opsx-superpowers. The plugin registers the four/opsx:commands as Claude Code slash commands; the Superpowers skills they invoke come bundled. -
Configure your project. Drop a
CLAUDE.mdat the project root if you don't have one. The plugin reads it for constraints, conventions, and pitfalls. It will populate the file with template sections on first run. -
Run your first explore. From inside the project: invoke
/opsx:explore <topic>on a small feature. The command reads the codebase, runssuperpowers:brainstormingfor the design pass, and (for UI work) opensvisual-companionto mock things up — all in one phase. When the requirements file flips toStatus: REVIEWED, chain/opsx:propose <topic>. The first full four-phase cycle takes thirty to sixty minutes on a small feature. After that, the muscle memory kicks in and you stop noticing the structure.
What the plugin gives you that the workflow doc alone doesn't: the commands enforce the linkage and the retros automatically. You don't have to remember to save the mock to a file — /opsx:explore saves it. You don't have to remember to migrate the spec to the README — /opsx:archive does it. The mechanism is built in, so the discipline becomes the default rather than an act of will.
A note on adoption: don't try to retrofit the full evolved stack onto a project that's deep into the earlier flow. Start the next feature with the new stack. After two or three features, the muscle is built and you can decide whether to fold it back across older work. Methodology is sticky; transitions work better when they're forward-looking.
Closing
There have been three evolutions so far. The first proved the integration worked. The second pinned it into schemas. The third made it portable as a plugin. Each one was built by running the previous one until the cracks showed, then designing the fix from what the cracks said. Nothing was planned ahead; everything was earned.
That cadence is what makes this an Agile project, not the Agile principles I mapped onto the commands. Each evolution produced a flow that ran end-to-end. Each next one ran better than the last. Every version was shippable; every next version was the previous one's spec. The methodology improved the same way the software it produces is supposed to improve — iteratively, by being used.
Your next evolution will be earned the same way. Run the stack. Notice what hurts. Fix the next thing. Package it when the fix is solid enough that you'd hand it to a colleague without a long explanation. That's how methodology compounds — not across one person's versions, but across practitioners.
If you've read this far, the next click is probably starting your own first evolution. The plugin's right there. The workflow doc's right there. The friction is yours to discover.
The methodology isn't done. It won't be. That's the point.
Thanks for reading along.