[3/6] Claude Code: Development Walkthrough

This is part 3 of a 6-part series on Claude Code.
3. Complete Development Walkthrough
Using the Finance project as an example, demonstrating Claude Code's practical application in all software development stages.
Finance Project Introduction
Project Positioning: Family financial management system for tracking assets, liabilities, expenses, and investments with multi-currency and multi-member support.
Core Features:
-
Asset & Liability Management:
- Multiple asset and liability types
- Time-series data model: Preserves historical changes for each asset/liability
- Basic CRUD operations and list displays
-
Expense Management:
- Hierarchical expense categories (major + subcategories)
- Monthly batch entry with historical data reference
- Three-level drill-down analysis (major category → subcategory → monthly trends)
-
Multi-Currency Support:
- Multiple mainstream currencies supported
- Real-time exchange rate retrieval (integrated external API)
- All amounts stored in original currency + USD equivalent
-
Data Visualization:
- Asset & liability trend charts
- Expense analysis with three-level drill-down
- Net worth change curves
Technical Complexity:
-
Backend Complexity:
- Time-series data modeling (asset/liability historical record management)
- Multi-currency conversion logic (stored procedures + Java Service layer division)
- Cross-table relational queries (assets, liabilities, expenses, exchange rates)
- RESTful API design (30+ endpoints)
-
Frontend Complexity:
- 33 Vue components, complex form interactions
- Various data visualizations (Chart.js integration)
- Responsive design (mobile adaptation)
-
Database Complexity:
- 25 tables, including time-series data, multi-currency, soft delete
- Stored procedures for complex aggregation calculations
- Data migration script management
Development Journey:
- Phase 1: Asset & liability management (core features)
- Phase 2: Asset & liability analysis (trend charts, net worth calculation)
- Phase 3: Expense management (categorization, entry, queries)
- Phase 4: Expense analysis (three-level drill-down, budget features)
- Phase 5: Investment management and analysis (completed)
This progressive feature expansion is a best practice when using Claude Code: Complete the core features first, validate architecture feasibility, then gradually add new features.
Application Interface:
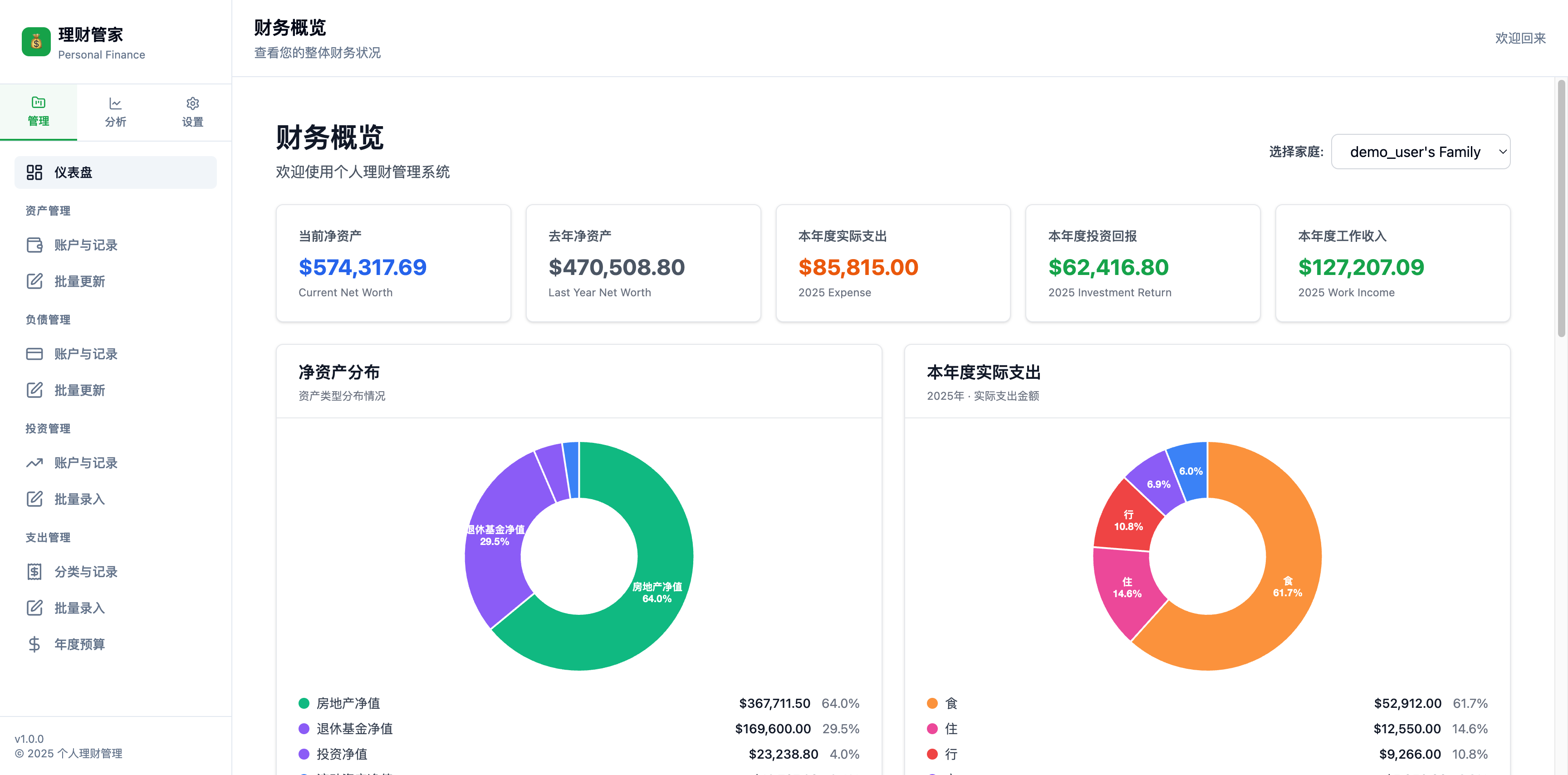
Dashboard interface showing asset & liability overview, trend analysis, and multi-dimensional data visualization
3.1 Initialization Phase: Building Project Skeleton
Traditional Approach vs. Claude Code
Traditional Approach (~2-4 hours):
1. Create Spring Boot project (Spring Initializr)
2. Configure Maven/Gradle
3. Create package structure (controller/service/repository)
4. Configure database connection (application.yml)
5. Create Vue project (vue create)
6. Configure routing, state management, API client
7. Setup Dockerfile and k8s configs
Claude Code Approach (Recommended) (20 minutes):
$ claude
You: Create a full-stack financial management system, referencing my previous match project (tennis match management) tech stack and directory structure.
**First core feature**: Asset & liability management
- Asset and liability type management
- Time-series data model: Record historical changes for each asset/liability
- Basic CRUD operations and list displays
Why This Approach:
- Reference Existing Project: Fix tech stack, avoid AI choosing inconsistent frameworks
- Clear Directory Architecture: Ensure clean project structure, easy to expand
- Focus on Core Features: Complete most important asset & liability management first, validate architecture
- Progressive Expansion: Clear feature iteration sequence (management → analysis → extension)
Real Results:
- ✅ Generated complete directory structure
- ✅ Configured Spring Security, JPA, CORS
- ✅ Created basic entities (User, Family) and corresponding CRUD
- ✅ Frontend routing, Axios configuration, Tailwind theme
- ❌ Needed manual adjustment of database connection string (AI used defaults)
Key Learnings:
- Let AI generate 80%, manually refine 20% - Initialization phase, AI can quickly build standard architecture
- Provide clear tech stack - Vague requirements lead AI to choose outdated or mismatched technologies
- Generate first, adjust later - Don't expect perfection first time, rapid iteration is more efficient
Optimization Practice: The Inception of CLAUDE.md
After initialization, I created the first version of CLAUDE.md:
# Finance App - Claude Code Guide
## Stack
Java 17 + Spring Boot 3.2 + Vue 3 + MySQL 8.0
## Critical Rules
- **ALWAYS use Maven wrapper** - `./mvnw` instead of `mvn`
- **NEVER commit backend/.env** - Contains DB credentials
Why Write CLAUDE.md So Early?
- ✅ Prevent AI from "forgetting" tech stack in subsequent sessions
- ✅ Record problems encountered on day one (e.g., mvn vs ./mvnw)
- ✅ Lay foundation for future
/clear + /catchupworkflow
3.2 Requirements Phase: From Vague Ideas to Precise Specs
My Requirements Workflow (Prevent AI Over-Design)
Step 1: High-Level Requirements
You: I want to implement expense management functionality, don't implement yet, help me break down requirements.
**Core requirements**:
- Expense category management (major + subcategories)
- Monthly batch entry
- Multi-currency support
**I particularly care about**:
- Data entry efficiency (complete all subcategories in one form)
- Historical data reference (show last 3 months)
Step 2: Review AI's Requirements Breakdown
Claude returns detailed requirement list, usually has over-design tendencies:
Claude: Here's the requirements breakdown:
1. Expense category management
- Major category CRUD
- Subcategory CRUD
- Category hierarchy management (major → subcategory)
2. Monthly entry
- Batch entry form
- Historical data display (last 3 months)
- Auto-save draft ❌ (over-design)
- Template function (copy last month) ❌ (not needed yet)
3. Multi-currency
- 7 currency support
- Real-time exchange rate retrieval
- Exchange rate history ❌ (phase 2)
4. Data validation
- Uniqueness constraints
- Amount range validation ❌ (unnecessary)
...
My Response:
You: Requirements 3.3 (exchange rate history), 2.2 (auto-save draft), 2.3 (template function), 4.2 (amount range validation) - don't do these yet.
Keep core features: category management, batch entry, multi-currency, basic validation.
Why This Approach:
- ✅ Prevent Scope Creep: AI tends to add "useful but non-essential" features
- ✅ Rapid Iteration: Do minimum viable version (MVP) first, expand based on actual needs
- ✅ Reduce Complexity: Avoid first version introducing too many features leading to prolonged implementation
3.3 Design Phase: Architecture Decisions & AI Boundaries
After requirements are clear, enter design phase. This is a human-led, AI-assisted phase.
Planning Mode: Systematic Design Process
For complex features (like expense management's three-level drill-down analysis), I use Planning Mode for systematic design:
$ claude --plan
You: Implement three-level drill-down for expense analysis, provide detailed design including:
1. **Data Model Design**
2. **Backend API Design**
3. **Frontend UI Mock**
4. **Test Case Design**
**Feature requirements**:
- Pie chart showing major category proportions
- Click major category → subcategory pie chart for that category
- Click subcategory → monthly bar chart for that subcategory
**UI Reference**:
- First feature: Start simple, pure white background + basic charts
- Subsequent features: Reference implemented AssetAnalysisView.vue style
(ensure consistent user experience)
Claude's Generated Plan (plan.md):
# Expense Analysis Three-Level Drill-Down - Design Plan
## 1. Data Model Design
- Use existing tables, no new fields needed
- Key field review (amount_usd, period, is_deleted)
## 2. Backend API Design
- GET /api/expenses/analysis/category-summary
- GET /api/expenses/analysis/subcategory/{categoryId}
- GET /api/expenses/analysis/monthly/{subcategoryId}
## 3. Frontend UI Mock
- Reference AssetAnalysisView.vue card layout
- Pie chart showing major category proportions
- Click to drill down to subcategory and monthly trends
## 4. Test Cases
- Data accuracy validation
- Cross-currency aggregation tests
- Drill-down state management tests
My Review Focus:
- Data Model: Carefully review each field, confirm necessity
- ✅ No new tables or fields needed
- ✅ Use existing amount_usd for aggregation
- UI Mock: Ensure consistency with existing interfaces
- ✅ Reference AssetAnalysisView.vue card style
- ✅ Use same color scheme and layout
- API Design: Check naming and parameters are reasonable
- ✅ RESTful style consistent
- ✅ Parameters concise and clear
After Approval:
You: Data model and API design are OK, start implementation.
Reference AssetAnalysisView.vue styles, maintain UI consistency.
Value of Planning Mode:
- ✅ Data Model Review: Avoid later database migration costs
- ✅ UI Consistency: Reference existing components, ensure experience
- ✅ Align Expectations - Confirm approach before writing code
- ✅ Discover Gaps - AI might think of edge cases you didn't
- ⚠️ Don't Over-Plan - Simple features (less than 3 files) just do it
Architecture Trade-offs: Human Decisions + AI Provides Options
AI struggles to make good architecture trade-offs independently. My two practical methods:
Method 1: Distill Architecture Principles from Existing System
After the first feature stabilizes, I summarize architecture design principles and write them into CLAUDE.md:
## Architecture Principles
**Time-Series Data**:
- Asset/Liability: NEVER update existing records, always INSERT new ones
- Reason: Historical tracking requirement
**Multi-Currency**:
- Store original currency + converted USD amount
- Use ExchangeRateService for all conversions
- Reason: Audit trail + performance
...
Why Important:
- New features automatically follow established principles
- Prevent AI from using different architectures for similar features
- Reduce long-term refactoring costs
Method 2: Small Feature Experiments + Multi-Option Comparison
For uncertain architecture decisions (like which layer for complex logic), I ask Claude for multiple options:
You: Annual financial summary logic is complex (cross-table joins, currency conversion, time range filtering), give me 3 implementation approaches:
1. MySQL stored procedure
2. Java Service layer calculation
3. Frontend real-time calculation
For each approach, analyze performance, maintainability, testing difficulty.
Don't implement yet, just compare approaches.
Claude's response:
| Approach | Performance | Maintainability | Testing Difficulty | Use Case |
|---|---|---|---|---|
| Stored Procedure | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐ | Large data, frequent queries |
| Java Service | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | Complex logic, need unit tests |
| Frontend Calculation | ⭐ | ⭐⭐⭐ | ⭐⭐⭐ | Small data, real-time interaction |
My Decision Process:
- Choose approach 1 (stored procedure) + approach 2 (Java Service) to implement one small feature each
- Compare actual results:
- Stored procedure: Query time from 3s down to 0.5s
- Java Service: High unit test coverage, but slow
- Final Approach: Hybrid
- Cross-table aggregation → Stored procedure
- Currency conversion + business logic → Java Service
- Frontend only for display
Codify Decision in CLAUDE.md:
**Complex Aggregation**:
- Use MySQL stored procedures for cross-table aggregation
- Java Service layer handles business logic + currency conversion
- Frontend: presentation only
Why This Approach:
- ✅ Small feature experiment low cost (1-2 hours)
- ✅ Actual comparison more reliable than theoretical analysis
- ✅ Once established, subsequent features stay consistent
3.4 Implementation Phase: Efficient Collaboration & Automation
This is where Claude Code delivers the most value.
Plan-based Cross-Layer Implementation
Since I've already made a Plan in the design phase (including data model, API, UI Mock), implementation necessarily involves cross-layer changes. Claude Code's advantages:
- ✅ Code Standards: Generated code follows project conventions
- ✅ Cross-Layer Consistency: API return format matches frontend expectations
- ✅ Automatic Integration: Most cases run without manual adjustments
Task: Add "expense budget" feature (Plan design already complete)
Plan Output (determined in design phase):
- Database:
expense_budgetstable - Backend: BudgetService, BudgetController
- Frontend: BudgetManagementView.vue
- API: GET/POST/PUT/DELETE /api/budgets
Implementation Order (my standard process):
- Database First: Create table and migration script
- Backend Implementation: Service → Controller → Unit tests
- Frontend Implementation: Component → API calls → Integration tests
Traditional Approach:
- Write backend (1-2 hours)
- Test API (30 minutes)
- Write frontend (1-2 hours)
- Integration (30 minutes)
- Write database script (30 minutes)
Claude Code Implementation Process (following my standard order):
Step 1: Database
- Create migration script, execute
/mysql-execto create table - ✅ Database ready
Step 2: Backend Implementation + Tests
- Generate Entity, Repository, Service, Controller
- Write unit tests and run
./mvnw test - Auto-fix issues found in tests
- ✅ Tests passing
Step 3: Frontend Implementation
- Create Vue component, reference existing style
- API calls automatically match backend format
- ✅ Frontend-backend integration successful
Why This Order Is Efficient:
- Database First: Avoid backend multiple table structure changes
- Backend Fully Tested: Ensure logic correct before frontend
- Frontend Direct Integration: API already validated, frontend implementation fast
Key Observation:
- Claude will autonomously run tests and fix errors (prerequisite: project has tests)
- Good cross-layer consistency: API return format automatically matches frontend expectations
- Follows existing code style: Frontend references ExpenseManagementView.vue, style consistent
The Power of Skills - Automated Workflows
Problem: Every database change requires manual operations (write script, copy password, execute, check)
Solution: Create /mysql-exec Skill, automatically load credentials and execute SQL
Effect:
# Before: 5 manual steps
# Now: 1 command
$ /mysql-exec database/add_budget_table.sql
✓ Executed successfully
Skills vs. Manual Commands Comparison:
| Scenario | Manual Commands | Skill |
|---|---|---|
| Time Cost | 2-3 minutes | 10 seconds |
| Password Leak Risk | High (history) | Low (encapsulated) |
| Repeatability | Need to remember commands | Consistency guaranteed |
| AI Usability | Need guidance | Auto-invoked |
My Other Skills:
/setup-java- Configure Java 17 + load env variables (must use every session)/git-commit-push- Atomic stage, commit, push (follows Conventional Commits)/docker-build-push- Multi-architecture image build (amd64/arm64)
CLAUDE.md Evolution in Implementation Phase
As development deepens, CLAUDE.md added implementation-level constraints:
## Backend Development
**NEVER modify JPA entities without checking existing records**
**ALWAYS use TimeService.getCurrentTimestamp()**
## Frontend Development
**ALWAYS use Composition API** - No Options API
**NEVER hardcode colors** - Use CSS variables
...
Why These Rules Matter?
TimeServicerule: Prevented a serious bug (timezone inconsistency caused data chaos)- JPA rule: Prevent AI from directly modifying entities causing data loss
- Composition API: Maintain code style consistency
3.5 Testing Phase: Iterative Quality Assurance
My Testing Workflow:
-
Unit Tests: Part of implementation phase
- After backend Service layer code generated, immediately generate unit tests
- Run
./mvnw testto verify logic correctness
-
Manual Usage Testing: Discover issues and improve experience
- After completing multi-layer implementation (database + backend + frontend), use it yourself first
- Find bugs → Fix → Test again
- No bugs → Try improving user experience → Back to design and implementation
-
Multiple Iterations: Until feature solidifies
- Repeat "use → find issues → improve" cycle
- Until feature is stable, experience satisfactory
-
Integration Testing: Final check before commit
- After feature solidifies, generate integration test cases
- Ensure end-to-end workflow correct
- Only commit code when all integration tests pass
This approach differs from traditional TDD (write tests first then code), better suited for rapid iteration mode in AI-assisted development.
Auto-Generated Unit Tests
Task: Write unit tests for ExchangeRateService
Claude automatically generates test code, covering main scenarios (caching, conversion, batch operations, exception handling)
Results:
- ✅ Coverage 85%+
- ✅ Found a bug: Negative amount not validated
- ❌ External API mock too complex, needed manual simplification
Integration Testing & Hook Validation
Challenge: Prevent AI from committing code when tests fail
Solution: Create Pre-Commit Hook (.claude/hooks/pre-tool-use.sh), force test validation before commit
Value of Hooks:
- ✅ Forced Validation - AI cannot skip tests
- ✅ Self-Correction - AI reads hook output and fixes issues
- ⚠️ Don't Overuse - Too many hooks confuse AI
3.6 Deployment Phase: Docker Containerization
My current deployment strategy:
- Docker image build (backend + frontend)
- Docker Compose local orchestration
- GitHub Actions auto-build and push to Docker Hub
(Kubernetes deployment not yet implemented, planned for future)
Docker Containerization
Claude generated complete Docker configuration:
- Backend Dockerfile: Multi-stage build (Maven build + JRE runtime)
- Frontend Dockerfile: Vue build + Nginx serving
- docker-compose.yml: Complete orchestration of MySQL + backend + frontend
Evaluation:
- ✅ Multi-stage build reduces image size
- ✅ Convenient for local development
- ✅ Clear environment variable management
GitHub Actions Auto-Build
Claude generated complete GitHub Actions workflow, implementing:
- Push to master: Test → Build → Push to Docker Hub
- Pull Request: Run tests only
Real Usage Effect:
- ✅ Complete automated CI/CD workflow
- ✅ Push both latest and commit SHA tags simultaneously
/docker-build-push Skill
To simplify local builds, created /docker-build-push Skill supporting multi-architecture image build (amd64/arm64)
Effect:
# Before: Multiple complex commands
# Now: One command completes
$ /docker-build-push
✓ Building backend (amd64, arm64)...
✓ Building frontend (amd64, arm64)...
✓ Pushed to Docker Hub